




Après un premier article sur l’anonymisation, je traiterai dans ce deuxième article de la pseudonymisation et apporterai des éléments de réponses à ces quelques questions :
qu’est ce que la pseudonymisation : il s’agit ici de la présenter telle qu’elle est définie dans le cadre du RGPD.
comment pseudonymiser ses données : quelles sont les techniques possibles.
comment mesurer l’efficacité du processus de pseudonymisation : sur quels critères peut-on se baser pour évaluer l’efficacité du processus.
quelle est la position du RGPD vis-à-vis du concept de pseudonymisation en tant que technique de protection des données personnelles.
pour finir, que faut-il retenir en bref.
Qu’est ce que la pseudonymisation
L’article 4 du RGPD définit la pseudonymisation comme étant “le traitement de données à caractère personnel de telle façon que celles-ci ne puissent plus être attribuées à une personne concernée précise sans avoir recours à des informations supplémentaires, pour autant que ces informations supplémentaires soient conservées séparément et soumises à des mesures techniques et organisationnelles afin de garantir que les données à caractère personnel ne sont pas attribuées à une personne physique identifiée ou identifiable.”
Sur la base de cette définition, il est possible de représenter le processus de pseudonymisation par le schéma simplifié suivant :
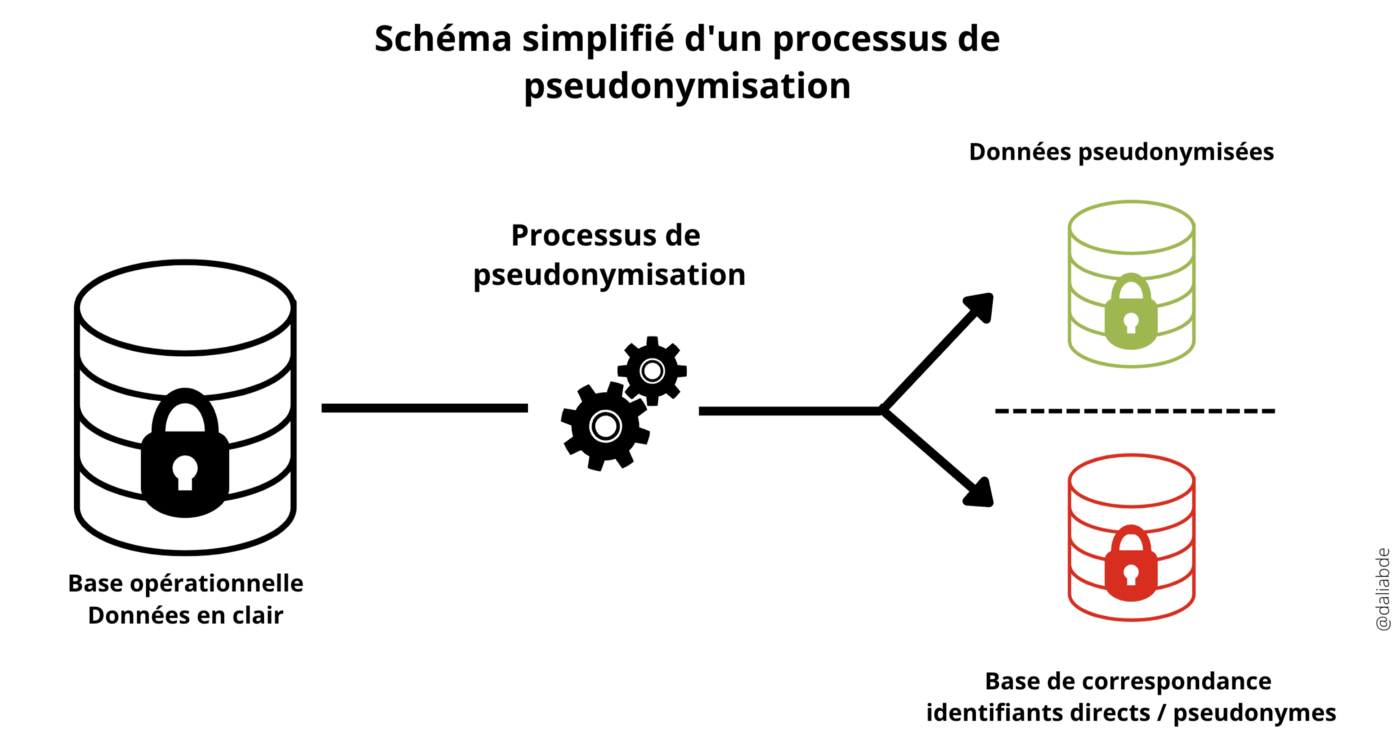
Comme on peut le constater, il ne suffit pas de remplacer les identifiants directs (nom, adresse, NIR…) par des pseudonymes (alias, numéros séquentiels…). C’est un processus particulier qui prend en entrée un jeu de données en clair, et qui fournit en sortie deux nouveaux éléments distincts : les données pseudonymisées et la base de correspondance identifiants directs — pseudonymes.
La pseudonymisation a donc des implications plus larges et pose un cadre particulièrement précis. Elle a pour objectif de protéger les données et les personnes auxquelles elles appartiennent afin de minimiser les risques de ré-identification, tout en permettant aux entreprises d’exploiter ces données.
Contrairement à l’anonymisation, elle ne dénature pas totalement et définitivement les données : il est toujours possible de retrouver l’identité d’une personne en lui associant des informations complémentaires. C’est en cela que la pseudonymisation est réversible.
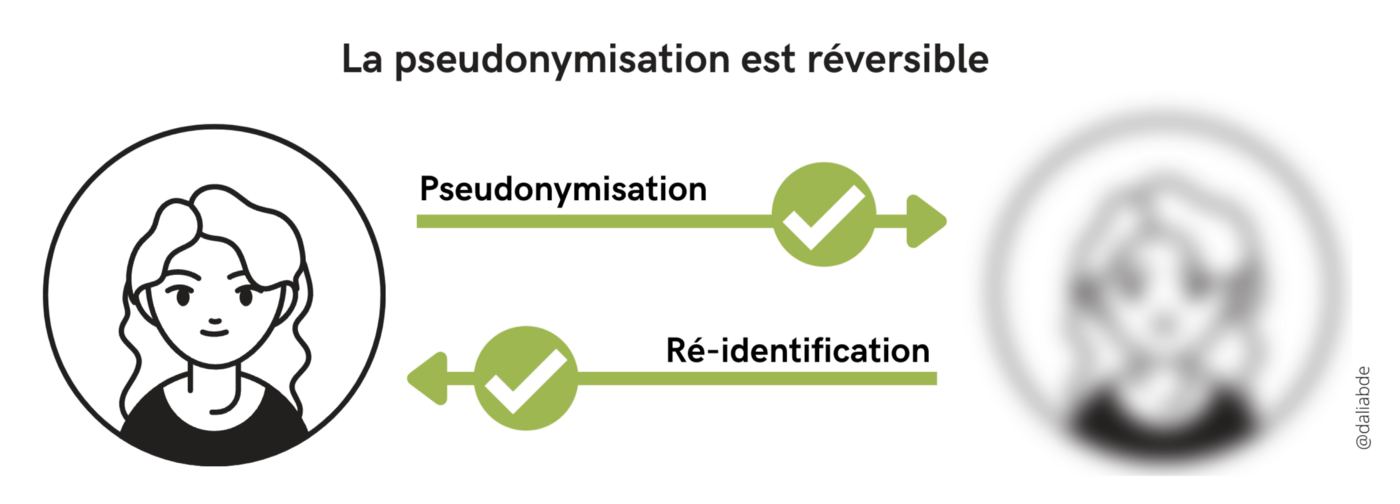
Pseudonymiser, oui mais comment?
Un processus de pseudonymisation s’inscrit avant tout dans un contexte. Plusieurs éléments entrent en considération dans le choix des techniques à implémenter, comme par exemple :
le volume des données à pseudonymiser,
la nature des données à pseudonymiser (données bancaires, de santé, adresse IP, identifiants de connexion,…),
les traitements et les infrastructures qui supportent ces traitements,
le niveau de fonctionnalité, de confidentialité et de sécurité recherchés en fonction des cas d’usages prévus,
les risques d’attaques de ré-identification, de discrimination, de fuite…,
le secteur dans lequel l’entreprise évolue, notamment si elle est soumise à une réglementation spécifique,
les moyens qu’il est possible de mettre en oeuvre pour la réussite du projet…
Ces éléments doivent être pris en compte conjointement, dès le lancement du projet et de manière transversale.
On peut citer 2 grandes familles de techniques :
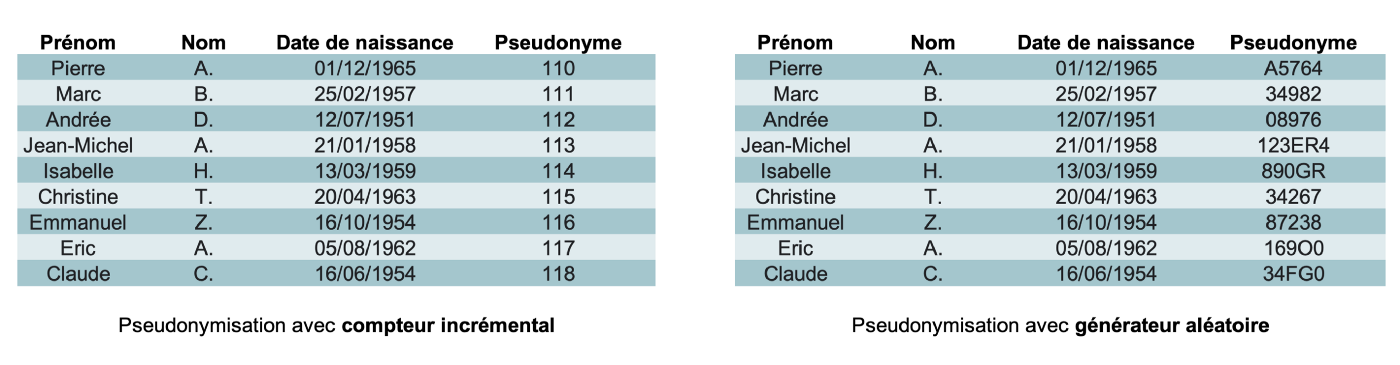
- les techniques permettant de produire des pseudonymes totalement indépendants des attributs qu’ils remplacent. Il s’agit par exemple des compteurs ou de générateurs aléatoires. Dans le cas des compteurs, les valeurs produites sont séquentielles et uniques. Dans le cas des générateurs, les valeurs sont générées de manière aléatoire et nécessitent une certaine vigilance dans la mesure où un même identifiant peut être attribué à plusieurs personnes distinctes.
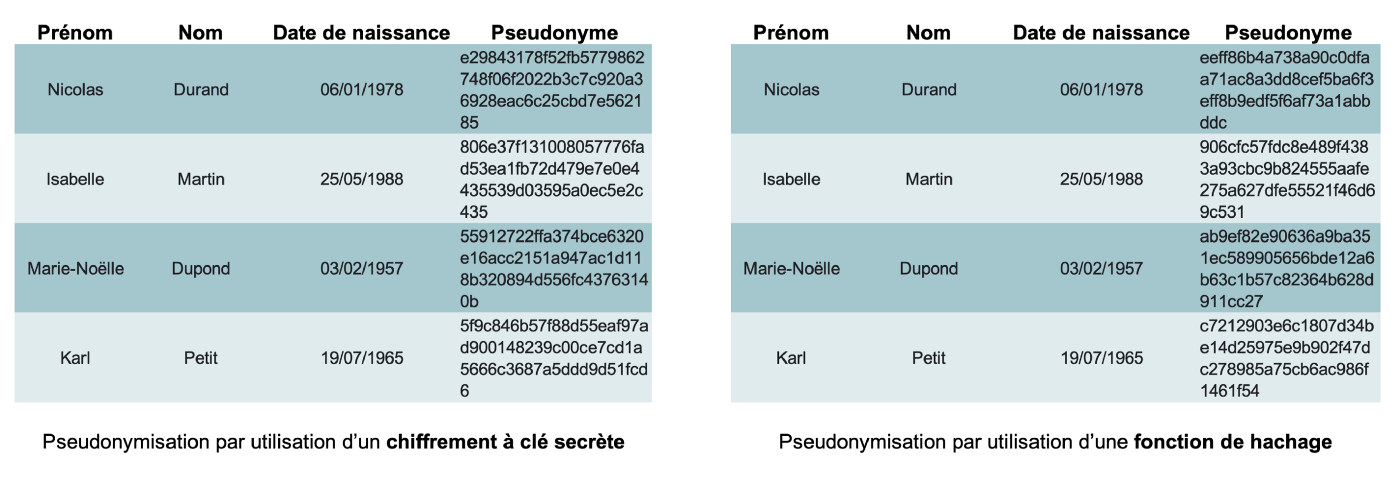
- les techniques issues de la cryptographie, telles que les fonctions de hachage ou le chiffrement. Dans ces cas, les pseudonymes découlent des attributs qu’ils remplacent puisque les pseudonymes sont créés à partir des attributs d’origine auxquels on a appliqué un algorithme afin de les protéger. On peut également citer la tokenisation, très utilisée notamment sur les données bancaires.
Comme pour l’anonymisation, il n’existe pas de solution unique et universelle qui s’appliquerait à toutes les situations*. Un processus de pseudonymisation **s’inscrit dans un contexte global et doit tenir compte de l’environnement externe et interne de l’entreprise.*
Comment mesurer l’efficacité de la pseudonymisation ?
Pour qu’il soit robuste et efficace, un processus de pseudonymisation doit être capable de limiter les risques et les attaques de ré-identification tout en permettant aux entreprises de traiter, d’exploiter et de valoriser ces mêmes données, de manière sécurisée et dans le cadre de la loi.
L’objectif est de trouver le meilleur équilibre entre utilité, fonctionnalité des données, niveaux de sécurité et risques de ré-identification.
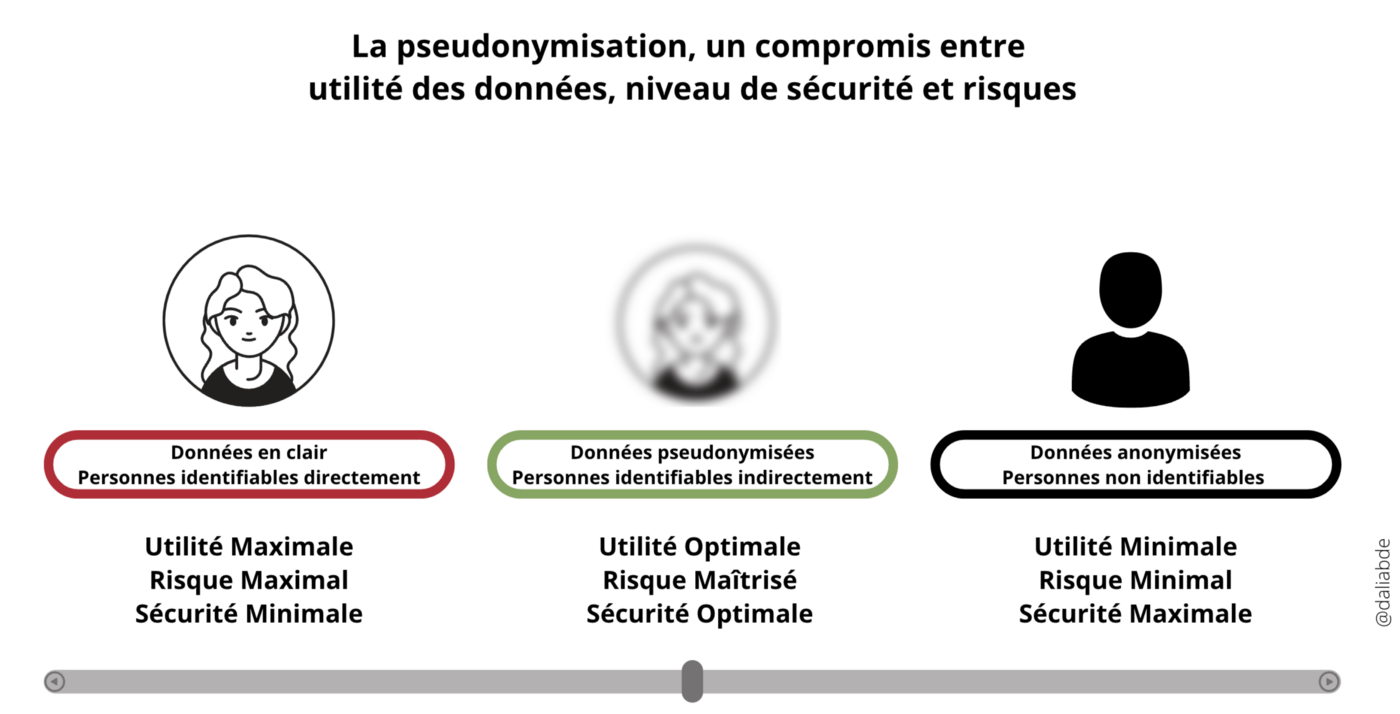
Schéma représentant la pseudonymisation comme la recherche d’un compromis entre utilité des données, niveau de sécurité et risques de ré-identification.
Cependant, il n’existe pas de critères d’évaluation du processus de pseudonymisation comme cela est le cas pour l’anonymisation. Il est toutefois possible de l’apprécier au regard des 3 exigences suivantes :
ré-identification sans informations supplémentaires : est-il possible d’identifier une personne physique sans recourir à des informations supplémentaires? Si la réponse est positive, alors les données ne sont pas pseudonymisées. Le cas échéant, les exigences suivantes ne s’appliquent pas.
stockage séparé des informations supplémentaires (pseudonymes, alias,…) : peut-on facilement accéder aux données supplémentaires permettant la ré-identification des personnes concernées? Si la réponse est positive, alors les données ne sont pas pseudonymisées.
mise en place de mesures de sécurité techniques et organisationnelles supplémentaires : la pseudonymisation est une mesure de sécurité reconnue et promue par le RGPD. Néanmoins, elle n’exclue pas le recours à d’autres mesures complémentaires. Ceci s’explique notamment par le fait que les données résultant d’un processus de pseudonymisation sont toujours considérées comme des données personnelles. S’il n’existe pas de mesures supplémentaires visant à garantir la sécurité des données pseudonymisées et des pseudonymes, alors on peut considérer le processus de pseudonymisation comme étant compromis.
Au-delà de ces exigences, il est essentiel, en amont du projet, d’évaluer les risques et les opportunités d’une part, et d’autre part, de définir des bonnes pratiques et des facteurs clés de succès propres à chaque organisation. Il est également important de garder à l’esprit que la pseudonymisation n’est pas un processus définitif. Il doit faire l’objet de constantes réévaluations dans la mesure où les menaces évoluent, au même titre que les techniques de pseudonymisation et les cas d’usages.
Un processus de pseudonymisation efficace doit aussi permettre de d’identifier et de maîtriser les risques de ré-identification de manière préventive et proactive*. Il doit reposer sur une politique de sécurité qui **protège l’ensemble de la chaîne de traitement de la donnée**, y compris des données pseudonymisées et des pseudonymes.*
Que dit le RGPD ?
Le RGPD encourage le recours à la pseudonymisation car elle permet de répondre à 3 exigences fondamentales :
se mettre en conformité vis-à-vis de la réglementation,
protéger les données personnelles en réduisant les risques de ré-identification, qu’ils soient portés par des acteurs externes ou internes à l’entreprise,
respecter les grands principes de protections des données personnelles : finalité, proportionnalité, pertinence, sécurité, confidentialité…
La pseudonymisation est donc à la fois une mesure de sécurité utile (art. 32 du RGPD), et un outil au service de la protection des données répondant aux principes de Privacy by Design et Privacy by Default (art. 25 du RGPD).
Il faut cependant garder à l’esprit que la ré-identification est toujours possible. Les données ne sont pas totalement dénaturées, elles conservent leur intégrité et il est toujours possible de les reconstituer notamment grâce aux données supplémentaires. De ce fait, les données pseudonymisées et les pseudonymes restent dans le champ d’application du RGPD.
Comme pour l’anonymisation, une approche basée sur les risques et les usages doit être adoptée de manière à évaluer le degré de protection requis qui permette à la fois de réduire les risques et de préserver leur utilité.
En conclusion ?
La pseudonymisation est un processus réversible de désidentification. Elle a pour objectif de minimiser les risques d’association entre un ensemble de données personnelles et la personne concernée. C’est une mesure protectrice à l’égard des personnes et de leurs données personnelles, mais aussi à l’égard des entreprises car elle va au-delà du simple remplacement d’éléments identificateurs.
En effet, protéger des données par pseudonymisation implique de sécuriser les données et les infrastructures qui les abritent et les traitent, par défaut et dès les premières étapes de collecte. Elle permet de mener une véritable réflexion sur la nature des données collectées et de se limiter au strict nécessaire . Enfin, elle aide à préserver leur intégrité, ce qui répond aux exigences de qualité nécessaires à la création de valeur.
La pseudonymisation des données personnelles revêt un enjeu crucial dans le contexte actuel. Elle doit s’inscrire dans la stratégie de sécurité, de gouvernance et de qualité de l’entreprise. Elle n’est pas du simple ressort des équipes data ou IT et nécessite une prise en charge transversale.
A suivre
Le chiffrement